分布式系统中数据库与缓存一致性的几种方案的解析
文章目录方案一:先更新数据库,再更新缓存方案二:先删除缓存,在更新数据库方案三:先更新数据库,再删除缓存双删方案的优化缓存删除失败怎么办?总结首先要说明的是,接下来无论是哪种方案都只能保证最终一致,无法做到强一致性。方案一:先更新数据库,再更新缓存异常场景:线程A比线程B先更新,但是由于网络等原因导致线程B先更新了缓存。然后A再把旧值更新到缓存中。这种异常场景除了设置过期时间,没有办法解决脏数据的
首先要说明的是,接下来无论是哪种方案都只能保证最终一致,无法做到强一致性。
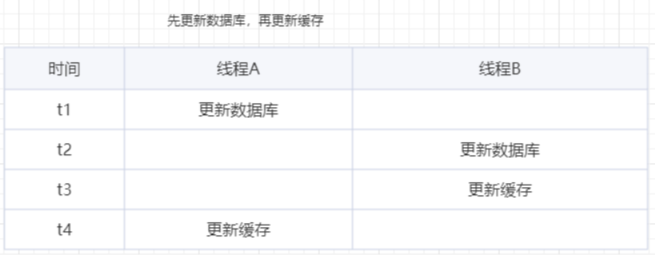
方案一:先更新数据库,再更新缓存
public void update() {
updateDB();
updateRedis();
}
异常场景:线程A比线程B先更新,但是由于网络等原因导致线程B先更新了缓存。然后A再把旧值更新到缓存中。这种异常场景除了设置过期时间,没有办法解决脏数据的问题。
从业务上考虑,如果你面对的是一个写多读少的场景,就会出现频繁更新缓存但是却没有人来读取的情况,浪费了性能。
其次,如果你用的缓存不是在简单的数据库值,而是那些要经过复杂计算才能得到缓存值的数据,这种方案无疑是很浪费的。
方案二:先删除缓存,在更新数据库
问题一:热点key的问题,如果是查询的热点key,很可能导致查询一下打到数据库了
解决方案:可以使用单机互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。这样可以避免大量请求直接打到数据库。
问题二:数据不一致
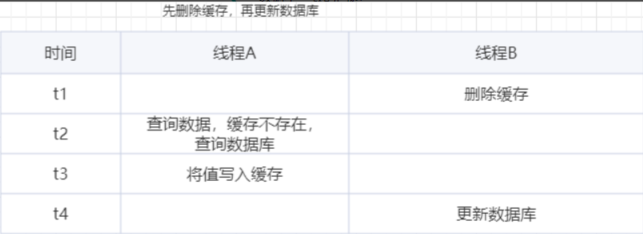
当线程B删除缓存后导致缓存失效,此时线程A进来查询,查到了旧值,并将值写入到缓存中。然后线程B才更新数据库。这个方案导致脏数据和方案一中的类似,如果没有其它步骤只能依靠缓存过期的时间来解决了。
方案一,方案二中导致缓存不一致发生的情况类似。都需要再多一步来保证数据一致性。
解决方案:延时双删策略
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}
就是再更新数据库后稍等一段时间再进行一次删除缓存的操作。
不过这个解决方案还有几个问题需要确认
-
删除应该休眠多久?
线程B延迟的时间应该大于线程A再写入缓存时间的。
需要测试项目中读取数据业务的耗时,写数据休眠的时间则再读取逻辑耗时加上百毫秒即可。这样就确保了读请求结束,写请求可以删除脏数据。
-
如果mysql主从读写分离又该休眠多久?
如果有主从同步延时,休眠时间再加上主从延时的时间即可。
-
性能下降怎么解决?
将删除的方案改为异步的方式。
方案三:先更新数据库,再删除缓存
方案三也就是我们的最终方案。这个也是facebook论文中提出的方案。下面是两篇论文有兴趣可以读一下。
https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf

先来讨论下这总异常情况发生的条件,首先要查询的时候缓存失效,然后要求更新数据库要比查询先返回并成功删除掉缓存。这个概率可以说非常非常之小了。虽然概率比1号方案更小但仍然存在。
解决方案:采用方案二中的双删方案。
双删方案的优化
如果再业务代码中耦合了异步删除的逻辑,一个是代码复杂度变高,另一个是不够优雅。
幸好,阿里开源了一个中间件canal,它可以定义mysql的binlog,就可以根据binlog来做业务,比如更新缓存,发kafka等操作。
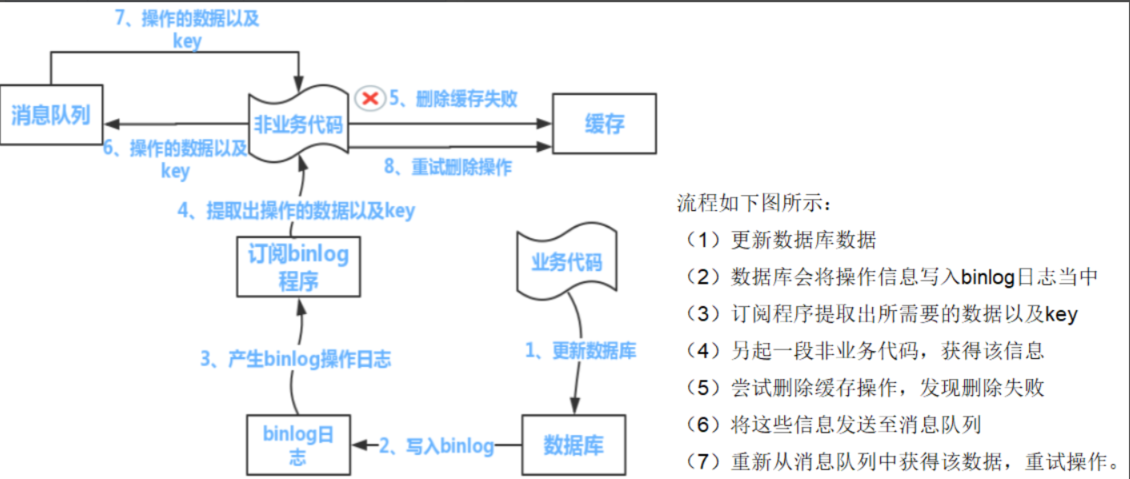
缓存删除失败怎么办?
经常再其他文章看见写所谓的因为删除缓存失败而选择某个方案的。我认为这是错误的。事实上,在这几个方案中都有删除失败的可能。如果要想确保一定不会失败,必须采用其他方案来保证。
总结
如果我们对数据的一致性要求没有那么高,直接使用方案三即可,这也是我们生产上最常使用的方案。如果要求较高,建议使用双删方案优化来确保数据库和缓存数据的最终一致性。

为所有Web3兴趣爱好者提供学习成长、分享交流、生态实践、资源工具等服务,作为Anome Land原住民可不断优先享受各种福利,共同打造全球最大的Web3 UGC游戏平台。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)